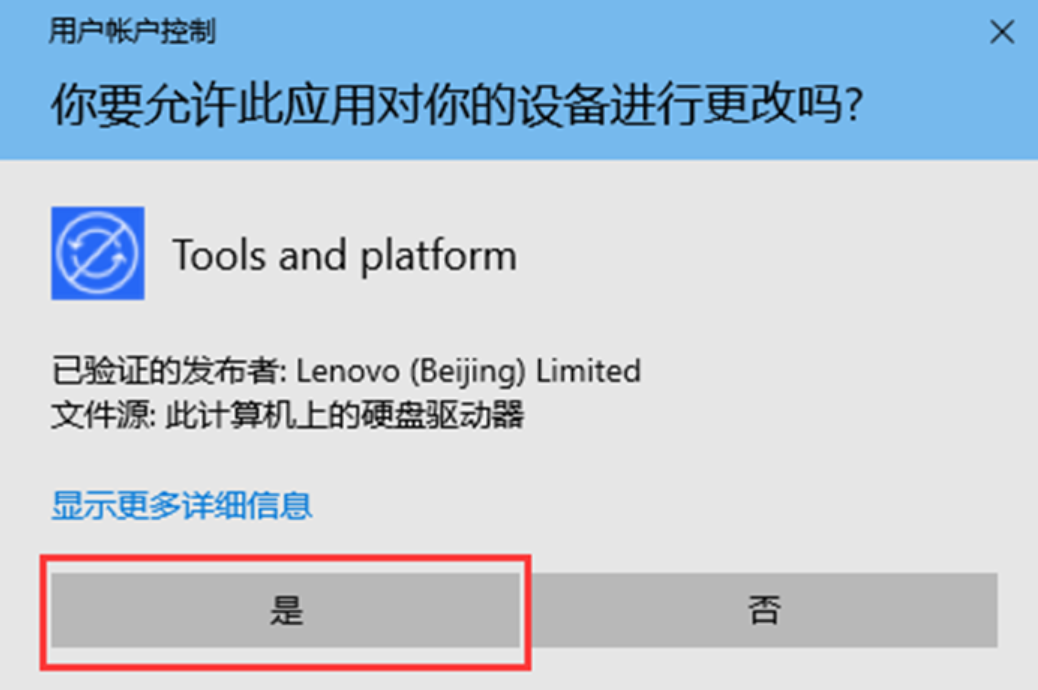
Lenovo Quick Fix:关闭或开启Win11系统的自动更新 Win11系统老是自动更新,每次更新后不仅拖慢我的运行速度,甚至打印机都不能用了,给我们带来了很多困扰 01 软件 的下载以及注意事项 小编提醒:您需要在电脑端下载并运行Lenovo Q
 2025-07-08
2025-07-08
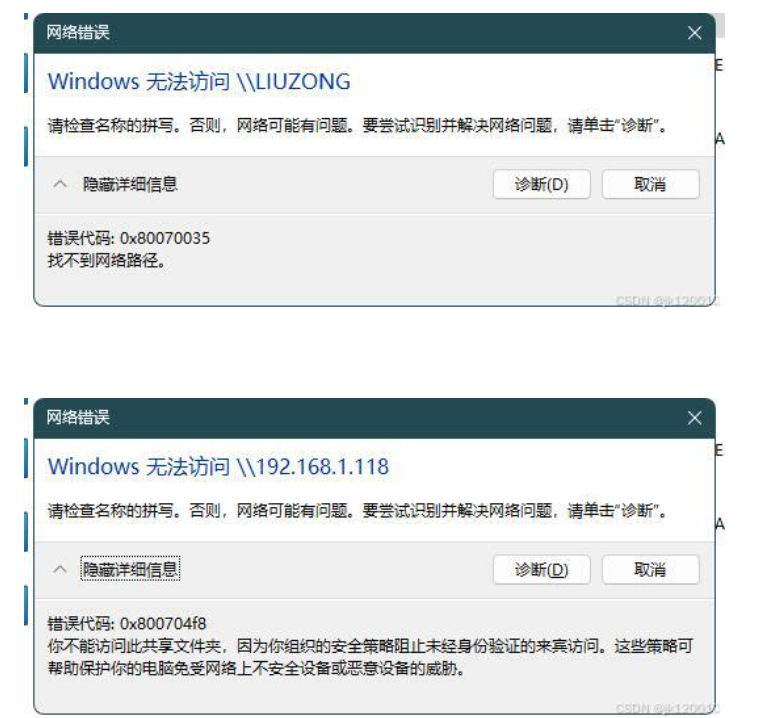
因为我对局域网内的所有电脑点击去都是0x80070035,找不到网络路径;而局域网内其他电脑互相访问都是正常的 ,说明问题肯定出现在我的电脑上,网路上搜索了很久都没有找到点子上,直到找到了微软的文章:控制 SMB 签名行为(预览版) | Microsoft Learn Windows 11 对
 2025-07-07
2025-07-07
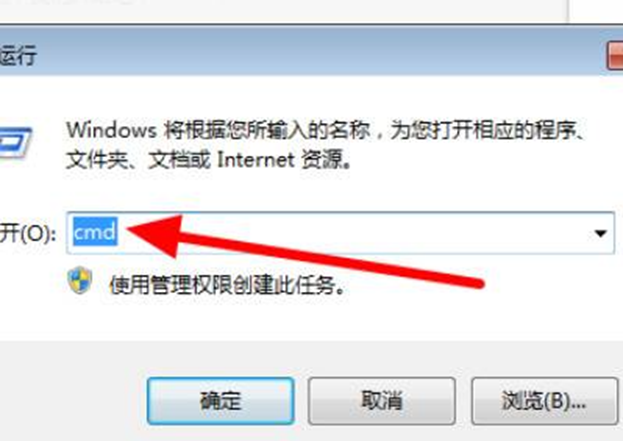
win10硬盘raw格式还原ntfs win10硬盘将raw格式还原成ntfs共分为4步,以下是华为MateBook X将raw格式还原成ntfs的详细步骤: 操作/步骤 1、同时按键盘上的Win+R键,在对弹出的对话框中输入CMD,按回
2025-07-07

切换 Apache 的 MPM(多处理模块)模式后,可以通过以下几种方法验证配置是否生效: 方法一:通过 Apache 内置命令查看当前 MPM Apache 提供了查看编译和运行时配置的命令,直接显示当前启用的 MPM: bash
 2025-07-06
2025-07-06
在 Linux 系统中,whereis命令是一个用于快速查找二进制程序、源代码文件和 man 手册页位置的工具。它通过搜索预定义的系统目录(如/bin、/sbin、/usr/bin、/usr/share/man等),高效定位目标文件的相关信息,适合快速查询系统自带工具或程序的安装位置。 一、基本语
 2025-07-04
2025-07-04
服务器作为存储数据信息的重要网络设备,能够保护企业重要数据的安全性,但是随着网络攻击的不断拓展,各个行业中的服务器也会遭受到不同类型的网络攻击,严重的会导致服务器业务中断出现故障,给企业带来巨大的经济损失。 那么,对于服务器故障的情况我们该如何避免呢? 对于避免服务器故障的情况,我们首先
2025-07-03
在 CentOS 上优化 Apache 性能需要从配置调整、资源分配、缓存策略等多方面入手,以下是关键优化方向和具体操作: 一、调整 Apache 核心配置(httpd.conf) Apache 的性能很大程度上取决于 httpd.conf(主配置)和 mpm.conf(多处理模块)的参数设置,
2025-07-03
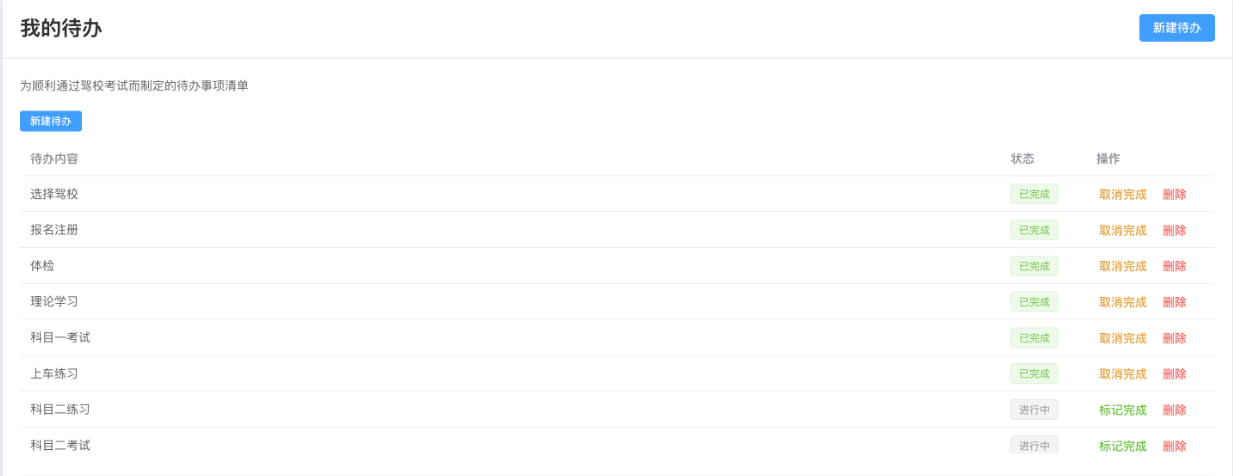
背景介绍 之前使用AI代码工具Trae基于Spring + Vue + MySql生成了一个输入要做事情AI自动生成待办任务列表的的小工具,效果如下: 本地跑通后正好有一台阿里云服务器和域名,准备把这个项目部署到云服务器实现远程访问,本文记录部署过程。 部署过程 云服务器配置 云服务器
2025-07-02
在 CentOS 上安装和配置 Web 服务器(以最常用的 Apache 和 Nginx 为例)的步骤如下: 一、安装 Apache(httpd) Apache 是最流行的 Web 服务器之一,适合大多数场景。 1. 安装 Apache bash
2025-07-02
CentOS 作为一款基于 Red Hat Enterprise Linux(RHEL)的开源发行版,与其他 Linux 发行版在定位、特性、适用场景等方面存在显著差异。以下从多个维度对比其与主流发行版的区别: 一、与 RHEL 系相关发行版的区别 CentOS 最直接的对比对象是同属 RHEL
2025-07-01