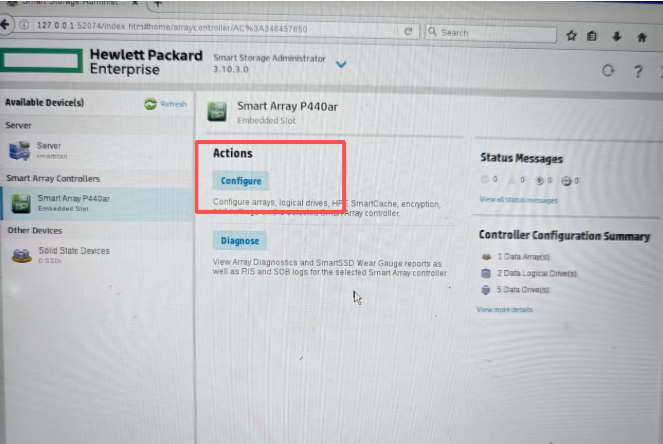
惠普服务器更换阵列卡无法进入系统 服务器:惠普 DL388 Gen9 阵列卡:Smart Array P440ar 现象:惠普服务器更换阵列卡无法进入系统: 1、开机按F10,进入如下界面 如下图可以看到阵列已经正常识别,但
 2026-04-08
2026-04-08
问题信息 表5-235 问题的基本信息 信息名称 信息内容 问题来源 2288H V5 该案例适用于 2288H V5 输出时间 2018-05-21
2026-03-30
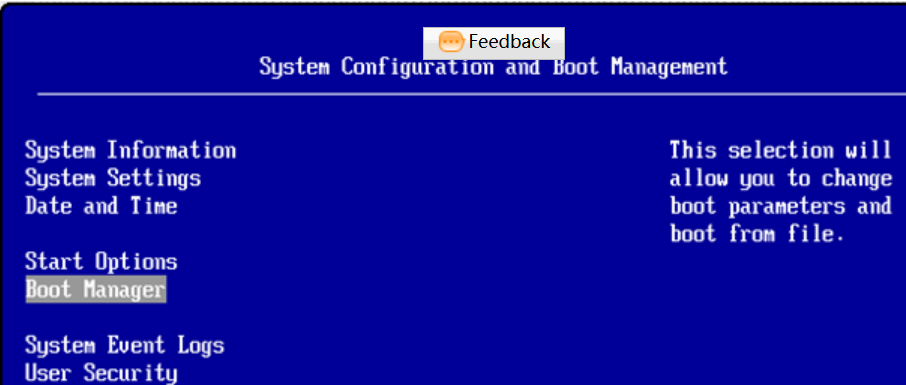
RH5485安装SUSE系统特定设置 问题现象描述 硬件配置: RH5485服务器。 问题现象: 安装SUSE系列的操作系统,安装过程中报错,无法完整安装;或者安装完重启系统后,服务器在POST阶段卡住,黑色屏幕上只有一个光标在闪烁。
2026-03-24
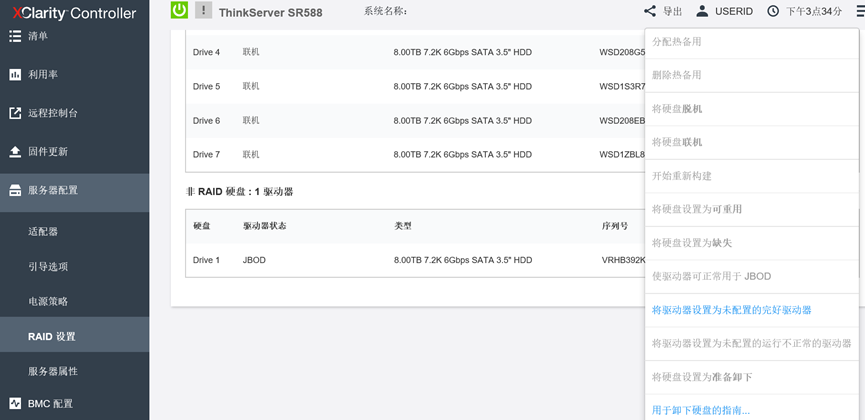
SR588更换硬盘后为GBOD状态 登录BMC 192.168.70.125 用户名USERID 密码PASSW0RD 在主界面点击服务器配置--RAID设置 将硬盘设置为未配置状态 再将硬盘设置为热备用,硬盘
2026-03-13
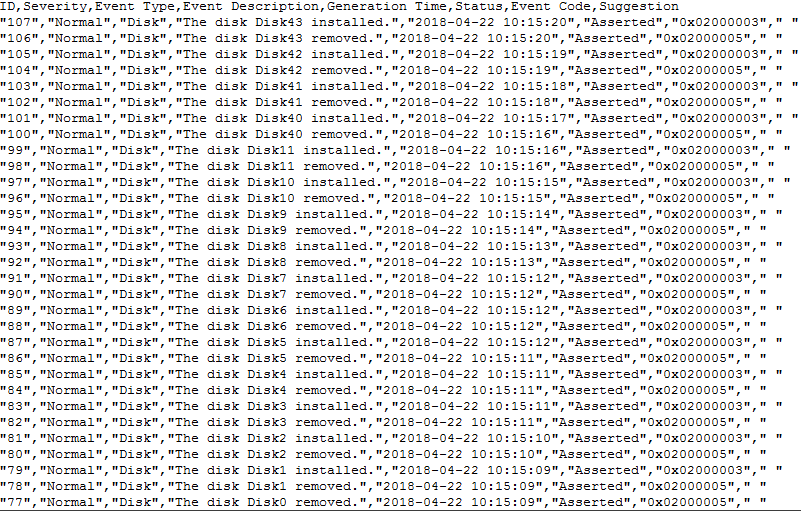
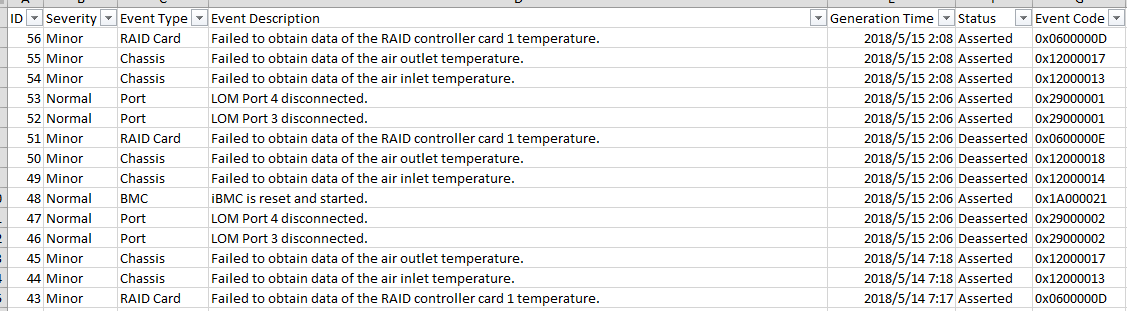
2288H V5服务器RAID卡下所有硬盘在位状态出现异常 问题现象描述 2288H V5服务器运行过程中突然报多块硬盘在位状态异常。 关键过程、根本原因分析 现象分析 从告警日志记录中,可以看到disk0-disk11(前置12盘硬盘背板)、disk4
2026-03-12
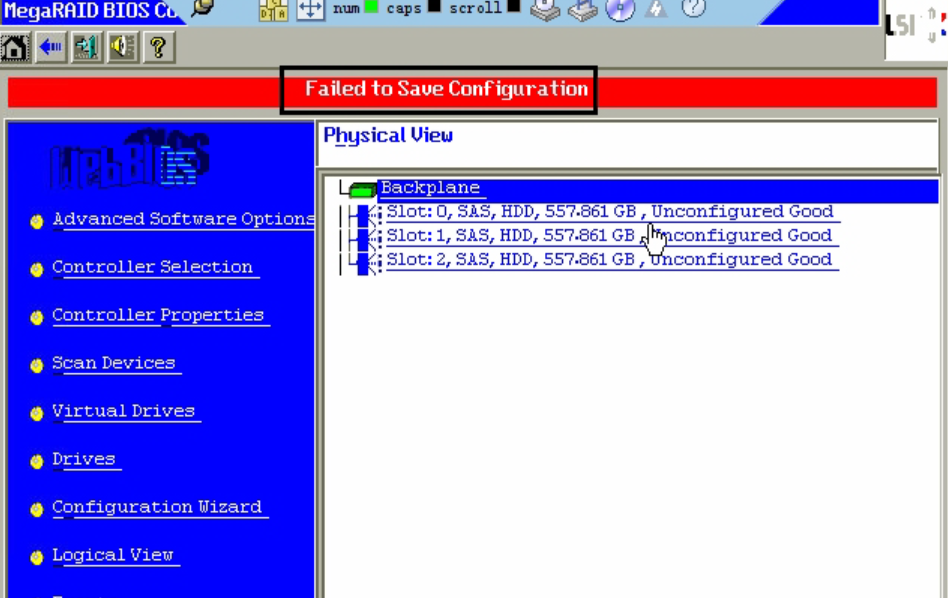
LSISAS2208卡硬盘后台格式化导致RAID组创建失败 问题信息 表5-97 问题的基本信息 信息名称 信息内容 问题来源 RH2288H V2 该案例适用于 使
2026-03-09

**一、服务器是什么** 服务器是一台专门为其他设备提供服务的高性能计算机,和普通PC相比更强调稳定性、可靠性和持续运行能力,需要7×24小时不间断工作。我们日常使用的每一个APP背后,都有大量服务器在支撑。 --- **二、服务器核心模块简介** **计算类** **CPU(处理器)**
 2026-03-03
2026-03-03
**一、系统信息查看** ```bash uname -a # 查看系统内核版本 cat /etc/os-release # 查看操作系统版本 hostname # 查看主机名 uptime # 查看系统运行时间和负载 date # 查看当前时间 ``` --- **二、硬件信息查
2026-03-02
RH2288V5风扇调速 服务器后置面板上有个MGMT口,网线一端连接MGMT,一端连自己的电脑 将您的电脑网卡的IP地址设置成同服务器管理地址同一个网段,如192.168.2.110 掩码255.225.
2026-02-06

NF8460M4S/NF8465M4S机器内存安装顺序异常导致机箱风扇转速过高 故障现象 机器风扇转速过高,达到7000多转,甚至更高。 故障原因 问题定位是因为内存没有按照正确的槽位顺序安装,DIMM JC温度无法读取,BMC认为温度无法获取而做的异常处理(把风扇转速调高),此现象并非硬件
2026-01-23