从紧急救援到根因分析,附自动化诊断工具开发**
一、生死时速:宕机现场紧急响应
场景描述:
- 凌晨3:15,监控系统告警:生产环境Ubuntu 22.04服务器无响应
- 用户访问全部超时,SSH连接失败
- 硬件指示灯:电源正常,硬盘黄灯闪烁
第一阶段响应流程:
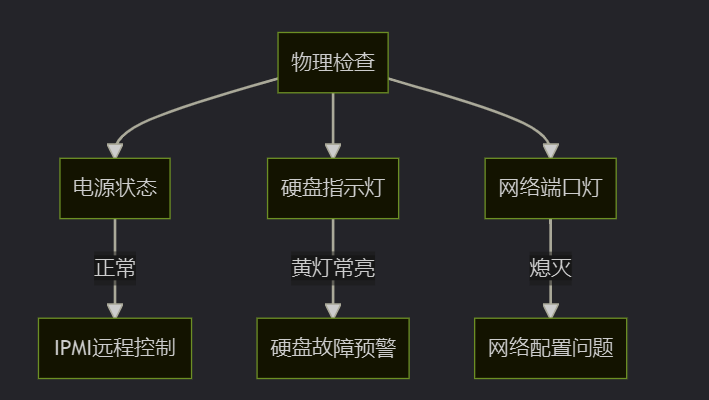
二、紧急救援:四步恢复系统访问
1. 通过IPMI强制重启
# 使用IPMItool远程管理
ipmitool -I lanplus -H 10.0.100.10 -U admin -P password power reset
注意:若硬件支持,优先通过BMC/IPMI访问,避免机房
2. 进入GRUB救援模式
启动时按Shift进入GRUB菜单:
# 选择Advanced options > recovery mode
# 挂载根目录读写权限
mount -o remount,rw
3. 检查文件系统完整性
# 扫描所有分区错误
fsck -y /dev/sda1
fsck -y /dev/sdb2
# 检查日志输出关键信息
dmesg | grep -i 'error' | tail -n 20
4. 临时禁用故障服务
# 停止可能引发崩溃的服务
systemctl stop docker containerd kubelet
三、深度排查:五维根因分析法
1. 内存泄漏分析
# 检查内核OOM日志
grep -i 'killed process' /var/log/syslog
# 查看内存使用历史
sar -r | tail -n 24
关键指标:
%memused> 90% 持续2小时kswapd0进程CPU占用100%
2. CPU异常定位
# 1. 查看最近高负载进程
journalctl --since "2 hours ago" | grep -i 'overload'
# 2. 生成CPU使用火焰图
perf record -F 99 -a -g -- sleep 30
perf script > out.perf
./FlameGraph/stackcollapse-perf.pl out.perf | ./FlameGraph/flamegraph.pl > cpu.svg
3. 磁盘I/O瓶颈
# 查看磁盘等待队列
iostat -dxm 1
# 输出示例:
# Device: await %util
# sda 120.3 98% # 严重阻塞!
# sdb 1.2 5%
# 定位高IO进程
iotop -oP
4. 网络风暴检测
# 抓取异常数据包
tcpdump -i eth0 -w panic.pcap
# 分析TOP连接
ss -s | grep 'Total:'
# Total: 32458 (kernel 0)
# TCP: 31245 (estab 28976, closed 2269, orphaned 143)
5. 内核崩溃分析
# 检查内核转储文件
apt install crash kdump-tools
crash /var/crash/2024070303/dump.2024070303
# 常用命令
crash> log # 查看崩溃日志
crash> bt # 打印调用栈
crash> ps # 查看崩溃时进程状态
四、根因定位:僵尸进程引发级联故障
证据链还原:
sequenceDiagram
数据库客户端->>Worker进程: 创建子进程处理查询
Worker进程-->>父进程: 返回结果后意外终止
父进程->>系统: 未回收子进程(僵尸)
循环 每5分钟
系统-->>僵尸进程表: 累计+150
end
系统->>内核: 进程PID耗尽
内核->>服务: 拒绝新进程创建
服务-->>用户: 服务不可用
关键日志佐证:
$ grep 'zombie' /var/log/kern.log
Jul 03 02:18:01 host kernel: [19876.123] Out of PIDs: fork failure in pid_namespace
Jul 03 02:33:45 host kernel: [20789.456] zombie created by pid 14523 (python3)
五、创新方案:自动化宕机分析工具
功能设计:
- 自动收集系统快照
- 生成可视化诊断报告
- 微信/邮件实时告警
代码实现:autopsy.sh
#!/bin/bash
# 服务器宕机自动诊断工具
REPORT_DIR="/var/autopsy/$(date +%Y%m%d_%H%M%S)"
mkdir -p $REPORT_DIR
# 1. 系统基础信息
top -b -n1 > $REPORT_DIR/top.txt
free -m > $REPORT_DIR/mem.txt
df -h > $REPORT_DIR/disk.txt
# 2. 进程级诊断
ps auxf > $REPORT_DIR/ps.txt
lsof +D / > $REPORT_DIR/lsof_all.txt 2>/dev/null
# 3. 网络状态分析
ss -tulnp > $REPORT_DIR/ss.txt
netstat -s > $REPORT_DIR/netstat.txt
# 4. 日志关键错误
journalctl -S "-1 hour" > $REPORT_DIR/journal.log
dmesg -T > $REPORT_DIR/dmesg.log
# 5. 生成HTML报告
echo "<html><body><h1>Autopsy Report</h1>" > $REPORT_DIR/report.html
echo "<h2>Top Processes</h2><pre>$(cat $REPORT_DIR/top.txt | head -n20)</pre>" >> $REPORT_DIR/report.html
echo "<h2>Memory Leak Check</h2><pre>$(grep -A5 'slabinfo' $REPORT_DIR/mem.txt)</pre>" >> $REPORT_DIR/report.html
# 微信告警(需安装企业微信机器人)
curl -s -X POST -H "Content-Type: application/json" \
-d '{"msgtype": "text", "text": {"content": "🚨 服务器宕机!诊断报告路径: '$REPORT_DIR'"}}' \
https://qyapi.weixin.qq.com/cgi-bin/webhook/send?key=YOUR_KEY
六、根治方案:构建抗崩溃体系
1. 僵尸进程防御层
# 在Python应用中添加子进程回收
import os
import signal
def handler(signum, frame):
os.waitpid(-1, os.WNOHANG)
signal.signal(signal.SIGCHLD, handler)
2. 资源隔离方案
# /etc/systemd/system/myapp.service
[Service]
MemoryMax=8G # 内存硬限制
CPUQuota=300% # 最多使用3核
TasksMax=1000 # 最大进程数
3. 高可用架构升级
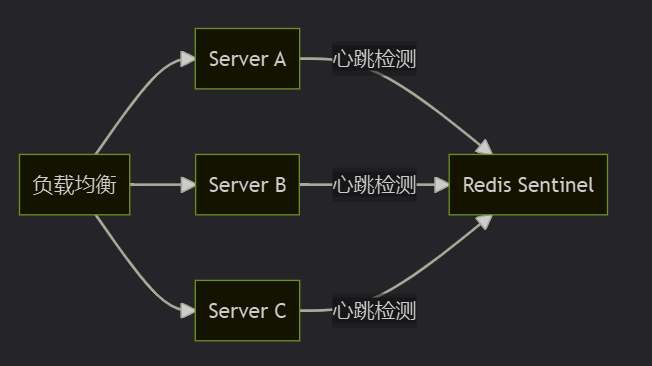
4. 智能熔断机制
# 当系统负载>5时自动拒绝新请求
import psutil
from flask import Flask, abort
app = Flask(__name__)
@app.before_request
def check_load():
if psutil.getloadavg()[0] > 5.0:
abort(503, "Server overload, please retry later")
七、预防性监控体系搭建
# prometheus.yml
scrape_configs:
- job_name: 'node'
static_configs:
- targets: ['localhost:9100']
# 关键告警规则
alerting_rules:
- alert: ZombieProcesses
expr: sum(count_over_time({__name__=~"processes.*"}[5m])) by (state) > 100
for: 10m
- alert: PIDExhaustion
expr: node_processes_max - node_processes_count < 100
Grafana看板关键面板:
- 进程状态热力图(运行/僵尸/睡眠)
- PID分配速率曲线
- 系统调用错误率
- 资源等待队列长度