Ollama在AI大模型领域与风靡一时的应用容器引擎Docker有着相似的角色。对于熟悉Docker的小伙伴,接触到Ollama时就会发现Ollama 的 shell 命令和 Docker 极其相似,比如 Ollama 通过ollama pull下载模型、ollama run运行模型 ,类似 Docker 拉取和运行镜像的命令。设计理念层面上,Docker 把应用程序及其依赖打包成镜像,方便在不同环境中部署和运行;与之对应的Ollama 则把大语言模型集合在一个仓库中,用户可以便捷地管理和运行各种 AI 模型,就像 Docker 管理镜像一样管理模型。
1、Ollama中模型的运行过程
在 Ollama 中运行一个模型的过程涉及模型管理、加载、推理等多个环节。下面从技术角度详细介绍一个完整的模型运行流程。
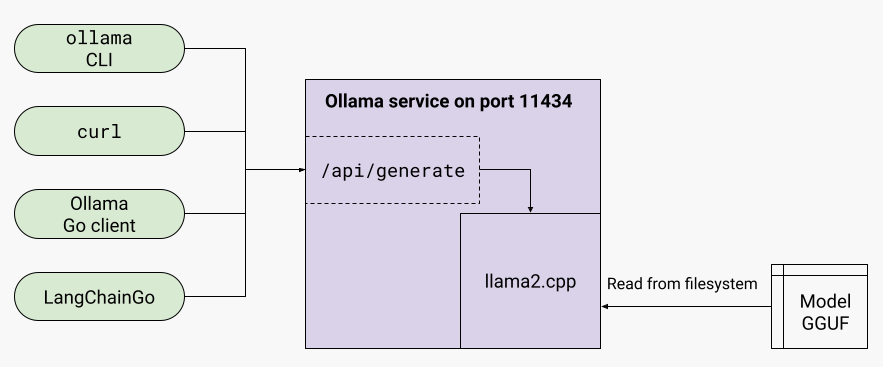
STEP 1:运行入口:启动 Ollama
当你运行命令ollama run llama2时,Ollama 会执行以下步骤:
(1)命令解析
• 使用 Cobra 解析命令行参数。
• 判断是否是 run 命令,并读取指定的模型名称 (llama2)。
(2)API 调用
• 如果是通过 API 运行模型(如通过 RESTful API 或 OpenAI API 调用),会通过 api 模块处理请求。
• API 请求数据包括模型名称、输入文本、参数等。
STEP 2:模型管理和加载
在模型运行前,Ollama 会检查模型的状态,执行以下步骤:
(1)模型检查
• 通过 internal/model/manager.go 检查模型是否已下载或存在于本地缓存。
• 如果模型不存在或需要更新,调用 ollama pull 自动从远程仓库下载模型。
(2)Modelfile 解析
• 使用 internal/modelfile/parser.go 解析模型的 Modelfile。
• Modelfile 中包含模型基于哪个基础模型 (FROM)、环境变量、指令和自定义配置。
FROM llama2
SYSTEM "You are a helpful assistant"(3)量化处理
• 如果模型支持量化(如 4-bit、8-bit),在 quantization.go 中执行量化加载。
• 使用 ggml 等格式加载量化模型,减少内存占用。
(4)推理引擎初始化
• 根据模型配置选择推理引擎。
• 默认情况下 Ollama 使用 llama.cpp 进行模型推理。
• 初始化推理上下文,分配内存和 GPU 资源。
STEP 3:推理执行**
加载完成后,模型进入推理阶段:
(1)请求解析
• 接收用户输入的 prompt,并进行预处理,包括分词和编码。
• Ollama 使用 tokenizer 将文本转换为 Token 序列。
(2) 模型前向推理
• 通过 internal/inference/engine.go 调用 llama.cpp 进行推理。
• 推理引擎会执行以下步骤:
- 读取 Token 序列并输入到神经网络中。
- 依次经过 Transformer 模型的各个层。
- 生成下一个 Token 的概率分布。
- 通过温度采样或 Top-K、Top-P 采样生成最终输出。
(3) 输出生成
• 推理结果通过 tokenizer 逆向转换为文本。
• Ollama 支持流式输出,用户可以实时看到推理结果。
STEP 4:API 或 CLI 返回结果
如果通过 API 请求运行模型,结果会通过 RESTful API 或 OpenAI 兼容 API 返回:
{
"id": "chatcmpl-123",
"object": "text_completion",
"created": 1234567890,
"model": "llama2",
"choices": [
{
"text": "你好!有什么可以帮助你的吗?",
"index": 0,
"finish_reason": "stop"
}
],
"usage": {
"prompt_tokens": 15,
"completion_tokens": 30,
"total_tokens": 45
}
}STEP 5:后处理和资源管理
完成推理后,Ollama 会执行清理和优化步骤:
(1)缓存管理:
• 将常用模型和权重保存在本地,减少重复加载的时间。
• 使用分块存储和校验文件完整性。
(2)内存释放:
• 及时释放不再需要的 GPU 和 CPU 资源。
(3)日志记录:
• 在 internal/utils/logger.go 中记录运行日志,便于调试和监控。
2、Ollama的技术架构
Ollama 的架构主要模型管理层、推理引擎层、API 服务层、数据存储与缓存等四部分组成。
模型管理层
• 支持多种 LLM 模型,包括 LLaMA 2/3、Mistral、Gemini 等。
• 使用 Modelfile 定义模型参数、环境配置和自定义指令。
• 支持模型导入与转换,便于从 Hugging Face 等平台迁移模型。
推理引擎层
•Ollama 使用 llama.cpp 进行高效推理,llama.cpp 以其轻量化和跨平台的特性而闻名。
• 支持量化模型推理(如 4-bit、8-bit),显著降低内存占用和推理时间。
• 支持 GPU 加速,充分利用 CUDA、Metal 等硬件加速。
API 服务层
• 提供 RESTful API,方便集成到 Web 应用或其他服务中。
• 支持 OpenAI API 兼容模式,方便开发者无缝迁移现有应用。
数据存储与缓存
• 本地缓存模型数据,避免重复下载。
• 使用分块管理模型文件,优化加载速度。
3、Ollama与llama.cpp、LLaMA、Transformer
Transformer、LLaMA、llama.cpp、ollama四者在人工智能领域的自然语言处理(NLP)中扮演不同的角色。简单来说,形成了一个从 架构设计 到 模型实现,再到 推理运行 和 用户友好化封装 的完整生态链。
Transformer -> LLaMA -> llama.cpp -> Ollama ->UserTransformer — 基础架构
Transformer 是由 Google 在 2017 年提出的神经网络架构,主要用于自然语言处理任务。它引入了 自注意力机制(Self-Attention),彻底改变了 NLP 的发展。
作用:
• 为现代大语言模型提供基础架构。
• 支持训练和运行包括 GPT、BERT、LLaMA 等模型。
关系:
LLaMA 的模型架构就是基于 Transformer 设计的,Transformer 是 LLaMA 的技术基础。
LLaMA — 大语言模型
LLaMA(Large Language Model Meta AI)是由 Meta(Facebook 母公司)推出的大型语言模型,专为研究和商业应用设计。
作用:
• 使用 Transformer 架构进行训练。
• 可以执行文本生成、对话理解、编写代码等任务。
关系:
LLaMA 是基于 Transformer 的具体实现,LLaMA 基于 Transformer 构建,是一个可运行的 AI 模型。
llama.cpp — 轻量级推理引擎
llama.cpp 是一个用 C++ 编写的轻量化推理引擎,用于高效地在本地设备上运行 LLaMA 等大型语言模型。
作用:
• 提供模型加载、推理执行等功能。
• 支持 CPU 和 GPU 推理,优化内存占用。
特点:
• 极致的性能优化,适合在消费级设备上运行。
• 兼容多种硬件,包括 macOS 的 Apple Silicon 和 NVIDIA GPU。
关系:
llama.cpp 使用 LLaMA 等模型进行推理,llama.cpp 是 LLaMA 模型的推理引擎。
Ollama — 模型管理和运行平台
Ollama 是一个基于 llama.cpp 构建的模型管理平台,它进一步封装了模型的下载、管理和运行过程。
作用:
• 提供简单的命令行工具,用户可以快速加载和运行 LLaMA 等模型。
• 支持自定义模型、模型版本管理等功能。
特点:
• 无需复杂环境配置,开箱即用。
• 支持 RESTful API 和本地推理。
关系:
• Ollama 使用 llama.cpp 作为推理后端执行 LLaMA 模型。
• Ollama 让普通用户无需了解底层细节即可运行大型语言模型。
• Ollama 是 llama.cpp 的封装,提供了易用的模型管理和推理工具