01 告警泛滥的三大根源
要解决问题,先得看清病根。当前网工面临的告警困境,主要来自以下三类:
01 阈值“一刀切”
- 问题:全网统一设置“CPU > 80%”就告警
- 后果:业务高峰期频繁误报,导致“告警疲劳”
- 建议:按设备角色、业务时段动态设置阈值(如:核心层85%,接入层90%;工作日 vs 夜间)
02 告警未关联
- 问题:链路中断、接口down、业务不可达分别发三条告警
- 后果:信息碎片化,定位耗时
- 解决:建立告警关联规则,自动聚合为“网络链路故障”主告警
03 缺乏闭环机制
- 问题:告警确认后无跟踪,整改无记录
- 后果:同类问题反复发生
- 核心:必须建立“告警→分析→处理→验证→归档”的完整闭环
02 四步实现高效闭环管理
01 第一步:分级分类,精准筛选
建议将告警分为三级:
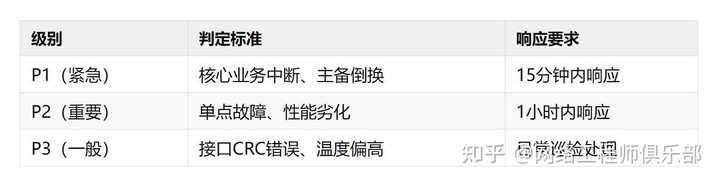

实操建议:在Zabbix、Prometheus等平台中配置告警标签(tag),便于自动化路由。
02 第二步:自动化预处理
利用脚本或编排工具(如Ansible、StackStorm)实现:
# 示例:自动检查接口状态并尝试恢复
if [ $(snmpget -v2c -c public switch1 ifOperStatus.1) == "down" ]; then
ssh admin@switch1 "shutdown gi 1/0/1; undo shutdown gi 1/0/1"
send_alert "Auto-recovery executed on gi 1/0/1"
fi
适用场景:光模块误插拔、临时链路抖动等可自愈问题。
03 第三步:根因分析(RCA)模板化
每次处理完P1/P2告警,填写标准化RCA表:
- 告警时间
- 影响范围
- 初步现象
- 检查步骤
- 根本原因
- 处理措施
- 改进建议(如:加备用链路、调整ACL策略)
价值:积累成“故障知识库”,新人也能快速上手。
04 第四步:闭环跟踪与复盘
03 工具推荐与配置建议
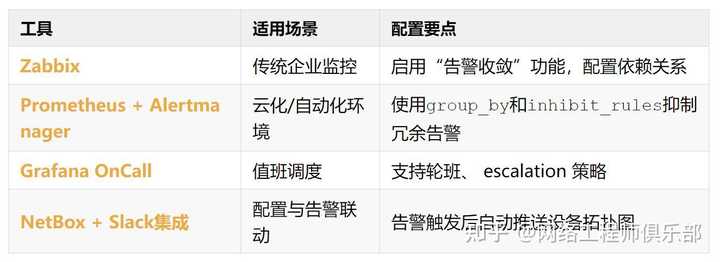

关键配置示例(Alertmanager):
inhibit_rules:
- source_match:
severity: 'critical'
target_match:
severity: 'warning'
equal: ['alertname', 'device']
含义:当设备产生严重告警时,自动抑制同一设备的警告级别告警。