一. 先看现象:打破你对 “地址” 的认知!
先通过一个简单的代码实验,感受虚拟地址的 “诡异” 之处(之前也提到过):
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h>
int g_val = 0; // 全局变量
int main()
{
pid_t id = fork(); // 创建子进程
if (id < 0)
{
perror("fork failed");
return 1;
}
else if (id == 0)
{ // 子进程
g_val = 100; // 子进程修改全局变量
printf("子进程[PID:%d]:g_val=%d,地址=%p\n", getpid(), g_val, &g_val);
}
else
{ // 父进程
sleep(3); // 等待子进程修改完成
printf("父进程[PID:%d]:g_val=%d,地址=%p\n", getpid(), g_val, &g_val);
}
sleep(1);
return 0;
}
编译运行结果:
子进程[PID:12345]:g_val=100,地址=0x80497e8
父进程[PID:12344]:g_val=0,地址=0x80497e8
关键现象:父子进程中g_val的地址完全相同,但值却不一样!
结论:这个地址绝对不是物理内存地址 —— 物理地址相同的变量不可能存储不同内容。Linux 中我们看到的所有地址,都是 虚拟地址,物理地址由操作系统统一管理,用户完全无法直接访问。OS 必须负责将 虚拟地址 转化成 物理地址 。
二. 进程地址空间布局:内存的 “逻辑分区”
进程地址空间是操作系统为每个进程分配的 “逻辑内存范围” ,它让每个进程都以为自己独占一块连续的内存,实际物理内存可能是离散的,甚至尚未分配。其经典布局(32位Linux)如下(从高地址到低地址)
2.1 地址空间分布详情
分区 核心作用 特点
内核空间(1G) 运行内核代码、管理硬件资源(如进程调度、内存分配) 用户进程不可直接访问,仅内核可操作
命令行参数与环境变量 存储 argv(命令行参数)和 env(环境变量) 高地址起始,向下生长
栈(Stack) 存储局部变量、函数调用栈帧 向下生长(地址从高到低分配),自动分配/释放
共享区(mmap) 映射共享库、文件、匿名共享内存 进程间可共享数据
堆(Heap) 动态内存分配(malloc / new) 向上生长(地址从低到高分配),需手动申请/释放
未初始化数据区(BSS) 存储未初始化的全局变量、静态变量 程序启动时初始化为 0
初始化数据区(Data) 存储已初始化的全局变量、静态变量 占用磁盘空间,加载时直接映射到内存
代码区(Text) 存储程序指令(二进制代码) 只读属性,防止意外修改
2.2 代码验证地址空间布局
通过打印不同区域的地址,验证上述布局:
#include<stdio.h>
#include<stdlib.h>
// 初始化全局变量(Data区)
int g_unval;
// 未初始化全局变量(BSS区)
int g_val = 100;
int main(int argc, char *argv[], char *env[])
{
const char *str = "helloworld";
// *str = 'H' // 错误
// 代码区(main函数地址)
printf("code addr: %p\n", main);
// 数据区
printf("init global addr: %p\n", &g_val);
printf("uninit global addr: %p\n", &g_unval);
// 静态变量(Data区)
static int test = 10;
// 如果是 &heap_mem 就在栈区,因为其本身就是个变量。
// 如果是 heap_mem 就在堆区。
char *heap_mem = (char*)malloc(10);
char *heap_mem1 = (char*)malloc(10);
char *heap_mem2 = (char*)malloc(10);
char *heap_mem3 = (char*)malloc(10);
// 堆区(堆向上生长,heap_mem2 > heap_mem1)
printf("heap addr: %p\n", heap_mem); //heap_mem(0), &heap_mem(1)
printf("heap addr: %p\n", heap_mem1); //heap_mem(0), &heap_mem(1)
printf("heap addr: %p\n", heap_mem2); //heap_mem(0), &heap_mem(1)
printf("heap addr: %p\n", heap_mem3); //heap_mem(0), &heap_mem(1)
// 静态数据区
printf("test static addr: %p\n", &test); //heap_mem(0), &heap_mem(1)
// 栈区(栈向下生长)
printf("stack addr: %p\n", &heap_mem); //heap_mem(0), &heap_mem(1)
printf("stack addr: %p\n", &heap_mem1); //heap_mem(0), &heap_mem(1)
printf("stack addr: %p\n", &heap_mem2); //heap_mem(0), &heap_mem(1)
printf("stack addr: %p\n", &heap_mem3); //heap_mem(0), &heap_mem(1)
// 只读字符串
printf("read only string addr: %p\n", str);
// 命令行参数与环境变量
for(int i = 0 ;i < argc; i++)
{
printf("argv[%d]: %p\n", i, argv[i]);
}
for(int i = 0; env[i]; i++)
{
printf("env[%d]: %p\n", i, env[i]);
}
return 0;
}
运行结果符合布局顺序(地址又高到低):
环境变量 > 命令行参数 > 栈区 > 堆区 > 数据区 > 代码区
三. 虚拟地址与物理地址:映射的核心逻辑
进程地址空间的核心是 “虚拟地址”,它与物理地址通过 “页表 + MMU” 实现映射,这是进程隔离、内存高效利用的关键。
3.1 核心概念
虚拟地址(VA):进程看到的地址,仅在进程内部有效,不同进程的虚拟地址可以重复;
物理地址(PA):真实硬件内存的地址,全局唯一,仅 OS 可以直接访问;
页表:内核为每个进程维护的 “地址映射表” ,记录虚拟地址到物理地址的队对应关系;
MMU(内存管理单元):CPU硬件组件,负责将虚拟地址通过页表转换为物理地址。
映射的一般流程:
进程执行时,CPU 收到的是虚拟地址;
MMU 根据当前进程的页表,将虚拟地址转换为物理地址;
CPU 通过物理地址访问真实的物理内存
若虚拟地址未映射物理地址(如 malloc 后还没写入数组),会触发 "缺页异常",内核为其分配物理内存并更新页表(这一步暂时只需要知道就行,后面还会再讲的)
3.2 父子进程地址映射的秘密
我们再来回顾一下开篇的实验,父子进程 g_val 虚拟地址相同但内容不同的原因如下:
fork 创建子进程时,会复制父进程的页表(浅拷贝),因此虚拟地址映射关系初始完全相同。
当子进程修改 g_val 时,触发 “写时拷贝” – 内核为子进程分配新的物理内存,修改子进程页表中 g_val 的映射关系,父进程的映射不变;
最终,父子进程的相同虚拟地址,映射到不同的物理地址,因此内容数据独立。
四. 内核数据结构:地址空间的 “管理者”
Linux 内核通过三个核心结构体管理进程地址空间,确保每个进程的地址空间独立且有序。
4.1 mm_struct(内存描述符)
每个进程的 task_struct(PCB)中都有一个 mm_struct 指针,它是进程地址空间的 “总描述符” ,记录地址空间的整体信息:
struct mm_struct {
struct vm_area_struct *mmap; // 指向虚拟内存区域链表
struct rb_root mm_rb; // 虚拟内存区域红黑树(快速查找)
unsigned long task_size; // 具有该结构体的进程的虚拟地址空间的大小
unsigned long start_code, end_code; // 代码区起始/结束地址
unsigned long start_data, end_data; // 数据区起始/结束地址
unsigned long start_brk, brk; // 堆区起始/当前结束地址
unsigned long start_stack; // 栈区起始地址
};
核心作用:描述地址空间的整体布局,组织虚拟内存区域;
每个进程有且仅有一个 mm_struct ,确保地址空间独立。
先来看看由 task_struct 到 mm_struct ,进程的地址空间的分布情况:
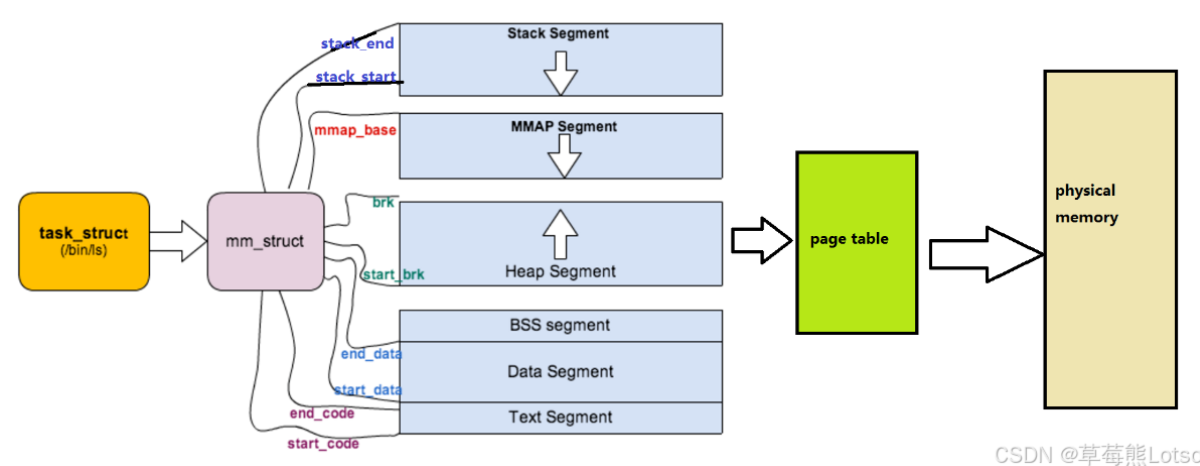
既然每一个进程都会有自己独立的 mm_struct ,操作系统肯定是要将这么多进程的 mm_struct 组织起来的!虚拟地址空间的组织方式有两种:
当虚拟区较少时采取单链表,由 mmap 指针指向这个链表;
当虚拟区间多时采取红黑树进行管理,由 mm_rb 指向这颗树。
Linux 内核使用 vm_area_struct 结构来表示一个独立的虚拟内存区域(VMA),由于每个进程不同质的虚拟内存区域功能和内部机制都不同,因此一个进程使用多个 vm_area_struct 结构来分表表示不同类型的虚拟内存区域。上面提到的两种组织方式使用的就是 vm_area_struct 结构来连接各个 VMA,方便进程快访问,同时也解决了比如栈区中间有段释放了那它剩下的两段区域该怎么管理的问题。
4.2 vm_area_struct(虚拟内存区域)
地址空间的每个分区(如代码区、堆区、栈区)都是一个 vm_area_struct,它描述单个虚拟内存区域的属性:
struct vm_area_struct {
unsigned long vm_start; // 区域起始虚拟地址
unsigned long vm_end; // 区域结束虚拟地址
struct vm_area_struct *vm_next; // 下一个虚拟区域
unsigned long vm_flags; // 区域属性(标志位,如只读、可写、可执行)
struct mm_struct *vm_mm; // 关联的mm_struct
};
所以我们可以对之前那个图再进程更细致的描述,如下图所示:
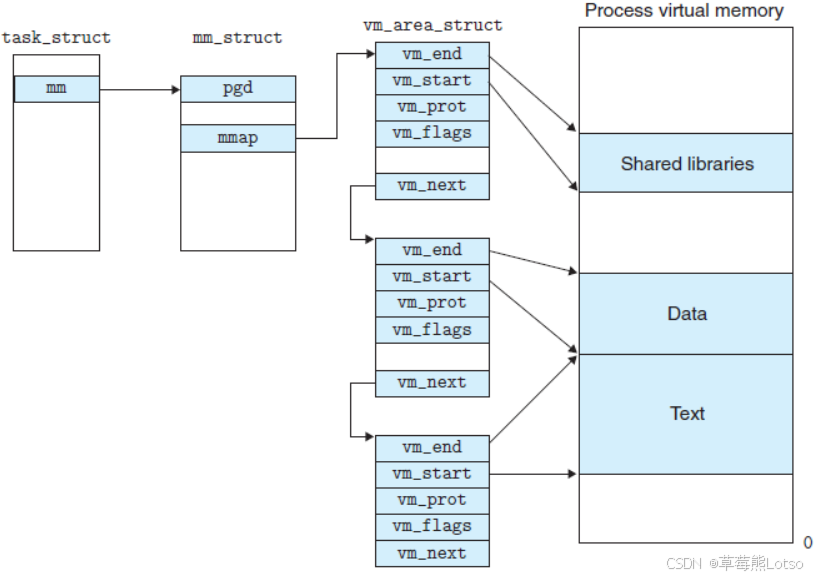
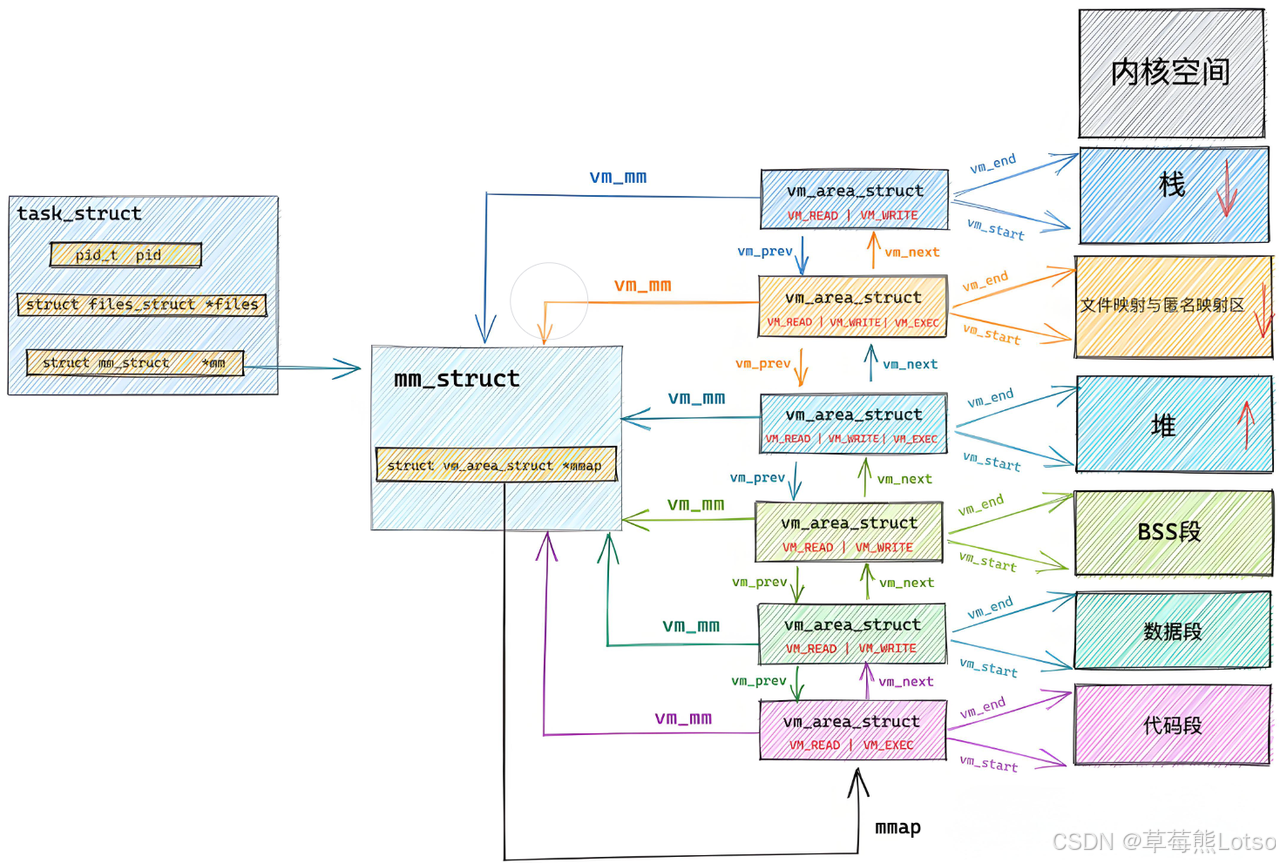
例如:代码区对应一个 vm_flags 为 “只读 + 可执行” 的 vm_area_struct;
内核通过链表(mmap)或红黑树(mm_rb)管理多个 vm_area_struct,快速查找指定虚拟地址所属区域。
数据结构关系:
task_struct(进程控制块)
↓
mm_struct(内存描述符)
↓
vm_area_struct(代码区)、vm_area_struct(堆区)、vm_area_struct(栈区)...(链表/红黑树组织)
↓
页表(虚拟地址→物理地址映射)
↓
MMU(硬件地址转换)
↓
物理内存
五. 为什么需要虚拟地址空间?
虚拟地址空间不是多余的,它解决了直接使用物理地址的三大痛点:

1. 进程隔离与安全
每个进程的虚拟地址空间独立,无法直接访问其他进程的虚拟地址,更无法直接操作物理内存;
内核通过页表控制访问权限(如代码区只读),防止进程恶意修改指令或系统内存,提升安全性。
2. 地址连续与物理离散
进程看到的虚拟地址是连续的,便于程序编写(如数组访问);
实际物理地址可以是离散的,内核通过页表将离散的物理内存 “拼接” 成连续的虚拟地址,提高物理内存利用率。
3. 延迟分配与高效利用
malloc或new时,内核仅在虚拟地址空间中预留空间,不分配物理内存;
当进程首次写入数据时,触发 “缺页异常”,内核才分配物理内存并建立映射,避免物理内存浪费。
4. 地址无关性
程序编译时无需关心实际物理地址,仅需使用虚拟地址;
内核可将程序加载到任意虚拟地址,通过页表映射到合适的物理地址,提高程序的可移植性。
❌️ 常见误区总结:
“程序地址空间”=“物理内存”:错误!程序地址空间是逻辑概念,物理内存是硬件资源,两者通过页表映射关联;
malloc 成功 = 物理内存已分配:错误!malloc 仅分配虚拟地址,物理内存是延迟分配的,首次写入才会真正分配;
虚拟地址相同 = 物理地址相同:错误!不同进程的相同虚拟地址,会通过各自的页表映射到不同物理地址,实现进程隔离;
栈和堆的生长方向固定:32 位 Linux 中栈向下、堆向上生长,但不是绝对的,具体由内核和编译器决定。
结尾:
🍓 我是草莓熊 Lotso!若这篇技术干货帮你打通了学习中的卡点:
👀 【关注】跟我一起深耕技术领域,从基础到进阶,见证每一次成长
❤️ 【点赞】让优质内容被更多人看见,让知识传递更有力量
⭐ 【收藏】把核心知识点、实战技巧存好,需要时直接查、随时用
💬 【评论】分享你的经验或疑问(比如曾踩过的技术坑?),一起交流避坑
🗳️ 【投票】用你的选择助力社区内容方向,告诉大家哪个技术点最该重点拆解
技术之路难免有困惑,但同行的人会让前进更有方向~愿我们都能在自己专注的领域里,一步步靠近心中的技术目标!
————————————————
版权声明:本文为CSDN博主「草莓熊Lotso」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/2503_91389547/article/details/155939397